
یادگیری ماشینی چیست؟
یادگیری ماشینی نوعی از هوش مصنوعی (AI) است که این امکان را برای یک سیستم فراهم میکند تا با استفاده از الگوریتمهای مختلف برای توصیف آنها به صورت مکرر از دادهها یاد بگیرد و با یادگیری از دادههای آموزشی که مدلهای دقیق تولید میکند، نتایج را پیشبینی کند.داشتن رایانه هایی که بدون اینکه به صراحت به آنها گفته شود می فهمند چه کاری باید انجام دهند، برای مدت طولانی تخیل را جذب کرده است. ایده ماشینی که می توانید سوار آن شوید (البته در صندلی راننده) که تمام رانندگی را انجام می دهد، عابران پیاده و چاله ها را شناسایی می کند و به تغییرات محیطی سریع و کارآمد پاسخ می دهد تا شما را ایمن به مقصد برساند – یعنی یادگیری ماشینی(ML) در عمل.
یاد گیری ماشینی چگونه کار می کند؟ بیایید با تجزیه و تحلیل فقط داده های تجاری شروع کنیم.
ML نوعی هوش مصنوعی است که به کسبوکارها اجازه میدهد تا حجم عظیمی از دادهها را درک کنند و از آن بیاموزند. به عنوان مثال، توییتر را در نظر بگیرید. طبق آمار اینترنت لایو، کاربران توییتر تقریباً 500 میلیون توییت در روز ارسال می کنند که معادل تقریباً 200 میلیارد توییت در سال است. تجزیه و تحلیل، طبقه بندی، مرتب سازی، یادگیری و پیش بینی چیزی با این تعداد توییت از نظر انسانی امکان پذیر نیست.
بیشتر بدانید
یادگیری ماشینی برای کسب اطلاعات ارزشمند به کار قابل توجهی نیاز دارد. برای استفاده حداکثری از ML، باید داده های تمیزی داشته باشید و بدانید چه سوالی در مورد آن دارید. سپس می توانید بهترین مدل و الگوریتم را انتخاب کنید تا به نفع کسب و کارتان باشد. ML فرآیند ساده یا آسانی نیست. موفقیت آن نیازمند کار مجدانه است.
یک چرخه زندگی برای ML وجود دارد:
· درك كردن. چرا به ML روی می آورید و به دنبال انجام یا یادگیری چه چیزی هستید.
· جمع آوری داده ها و پاکسازی. شما مقدار داده ای را که نیاز دارید، و به همان اندازه که لازم است ، تمیز است تا بینش های مورد نیاز را در اختیار شما قرار دهد.
· انتخاب ویژگی شامل تعیین داده هایی است که برای ایجاد یک مدل ML باید به ML وارد کنید. بسته به نوع الگوریتم مورد استفاده، روشهای مختلفی برای کمک به انتخاب ویژگیها وجود دارد. به عنوان مثال، فرض کنید می خواهید از الگوریتم درخت تصمیم استفاده کنید. در این صورت، تحلیلگر یا ابزار مدلسازی میتواند یک «امتیاز جذابیت» باشد ، به عنوان مثال، ستونهایی در پایگاه داده اعمال کند تا تعیین کند که آیا آن دادهها باید برای ساخت مدل شما استفاده شوند یا خیر.
· انتخاب مدل انتخاب فایل که برای پردازش و جستجوی موارد خاص در داده ها آموزش داده شده است. به یک مدل الگوریتمی داده می شود تا با آن کار کند و داده های آزمایشی این دو را ترکیب کرده و نتیجه گیری های خود را توسعه می دهد.
· آموزش و تنظیم. نتایجی که مدل برای شما پیدا کرده است تا اطمینان حاصل شود که پاسخ سؤالات خود را دریافت خواهید کرد.
· ارزیابی مدل و الگوریتم برای تعیین اینکه آیا برای استفاده آماده است یا اینکه باید چند مرحله به عقب برگردید و مدل، ویژگی، الگوریتم یا داده های خود را برای دستیابی به اهداف خود اصلاح کنید.
· استقرار مدل آموزش دیده در تولید.
· بررسی خروجی مدل موجود در تولید .
یادگیری ماشین برای چه مواردی استفاده می شود؟ برنامه های کاربردی یادگیری ماشین
یادگیری ماشینی راهی برای کسب و کارها برای درک و یادگیری از داده های خود است. یک کسب و کار می تواند از آن برای تعداد زیادی زیرشاخه استفاده کند. مورد استفاده بستگی به این دارد که آیا یک شرکت در تلاش برای بهبود فروش، ارائه ویژگی جستجو، ادغام دستورات صوتی در محصول خود، یا ایجاد یک خودروی خودران است.
زیرشاخه های یادگیری ماشین
ML دارای مجموعه ای فوق العاده از کاربردها در تجارت امروزی است و تنها می تواند در طول زمان افزایش یابد و بهبود یابد. زیرشاخههای ML شامل توصیههای رسانههای اجتماعی و محصول، تشخیص تصویر، تشخیص سلامت، ترجمه زبان، تشخیص گفتار و دادهکاوی است.
پلتفرمهای رسانههای اجتماعی مانند فیسبوک، اینستاگرام یا لینکدین از ML برای پیشنهاد صفحاتی برای دنبال کردن یا گروههایی برای پیوستن بر اساس پستهایی که دوست دارید استفاده میکنند. دادههای تاریخی از آنچه دیگران پسندیدهاند یا پستهایی شبیه آنچه شما دوست داشتهاید را میگیرد، آن پیشنهادها را به شما میدهد یا به فید شما اضافه میکند.
همچنین میتوانید از ML در یک سایت تجارت الکترونیک برای ارائه توصیههای محصول بر اساس خریدهای قبلی، جستجوهای شما و سایر اقدامات کاربران مشابه شما استفاده کنید.
امروزه یکی از کاربردهای مهم ML برای تشخیص تصویر است. پلتفرم های رسانه های اجتماعی برچسب گذاری افراد در عکس های خود را بر اساس ML توصیه کرده اند. پلیس توانسته است از آن استفاده کند و به دنبال مظنونان در تصاویر یا فیلم ها بگردد. با انبوهی از دوربینهای نصب شده در فرودگاهها، فروشگاهها و زنگهای درها، میتوان فهمید که چه کسی مرتکب جرم شده یا مجرم کجا رفته است.
تشخیص سلامتی نیز استفاده خوبی از ML است. پس از یک رویداد مانند حمله قلبی، می توان به عقب برگشت و علائم هشدار دهنده ای را مشاهده کرد که نادیده گرفته شده اند. سیستمی که توسط پزشکان یا بیمارستان ها استفاده می شود می تواند به سوابق پزشکی گذشته داده شود و یاد بگیرد که اتصالات ورودی (رفتار، نتیجه آزمایش، یا علامت) را به خروجی (مثلاً حمله قلبی) ببیند. سپس وقتی پزشک به آنها غذا می دهد. یادداشت ها و نتایج آزمایش در سیستم در آینده، دستگاه می تواند علائم حمله قلبی را بسیار مطمئن تر از انسان تشخیص دهد تا بیمار و پزشک بتوانند تغییراتی را برای جلوگیری از آن ایجاد کنند.
ترجمه زبان در صفحات وب یا برنامهها برای پلتفرمهای تلفن همراه نمونه دیگری از ML است. برخی از برنامهها نسبت به سایرین کار بهتری انجام میدهند، که به مدل، تکنیک و الگوریتمهای ML برمیگردد که از آنها استفاده میکنند.
امروزه یکی از کاربردهای روزمره ML در بانکداری و کارت های اعتباری است. نشانههایی از کلاهبرداری وجود دارد که ML میتواند به سرعت آنها را شناسایی کند و انسانها زمان زیادی برای کشف آنها، اگر اصلاً داشته باشند، طول میکشد. انبوهی از تراکنشهایی که بررسی شده و برچسبگذاری شدهاند (تقلب یا نه) میتوانند به ML اجازه دهند تا در آینده متوجه تقلب در یک تراکنش واحد شود. ML برای داده کاوی فوق العاده است.
داده کاوی
داده کاوی نوعی از ML است که داده ها را برای پیش بینی یا کشف الگوها در داده های بزرگ تجزیه و تحلیل می کند. این اصطلاح کمی گمراهکننده است، زیرا به هیچکس نیاز ندارد، خواه بازیگر یا کارمند بدی باشد که در دادههای شما ریشهیابی کند تا بخشی از دادههای مفید را پیدا کند. در عوض، این فرآیند شامل کشف الگوهایی در دادهها میشود که برای تصمیمگیری در آینده مفید هستند.
به عنوان مثال، یک شرکت کارت اعتباری را در نظر بگیرید. اگر کارت اعتباری دارید، بانک شما احتمالاً در مواقعی به شما از فعالیت مشکوکی در کارت خود اطلاع داده است. چگونه بانک چنین فعالیتی را به سرعت تشخیص می دهد و یک هشدار تقریباً آنی ارسال می کند؟ این داده کاوی مداوم است که این محافظت در برابر کلاهبرداری را امکان پذیر می کند. از اوایل سال 2020، بیش از 1.1 تریلیون کارت تنها در ایالات متحده صادر شده است. تعداد تراکنشهای این کارتها دادههای متنوعی را برای استخراج، جستجوی الگو و یادگیری شناسایی تراکنشهای مشکوک در آینده تولید میکند.
یادگیری عمیق
یادگیری عمیق نوع خاصی از ML بر اساس شبکه های عصبی است. یک شبکه عصبی برای تقلید از نحوه عملکرد نورون های مغز انسان برای تصمیم گیری یا درک چیزی کار می کند. به عنوان مثال، یک کودک شش ساله می تواند به یک چهره نگاه کند و مادرش را از محافظ عبور تشخیص دهد، زیرا مغز بسیاری از جزئیات را به سرعت تجزیه و تحلیل می کند – رنگ مو، ویژگی های صورت، زخم ها و غیره – همه در یک چشم به هم زدن. یادگیری ماشینی آن را در قالب یادگیری عمیق تکرار می کند.
یک شبکه عصبی دارای 3 تا 5 لایه است: یک لایه ورودی، یک تا سه لایه پنهان و یک لایه خروجی. موارد پنهان تصمیم می گیرند که به سمت لایه خروجی یا نتیجه گیری کار کنند. چه رنگ مویی؟ چه رنگ چشمی آیا جای زخم وجود دارد؟ با افزایش لایه ها به صدها، به آن یادگیری عمیق می گویند.
انواع یادگیری ماشین
اساساً 4 نوع الگوریتم یادگیری ماشین وجود دارد: تحت نظارت، نیمه نظارت، بدون نظارت و تقویت شده. کارشناسان
ML بر این باورند که تقریباً 70 درصد از الگوریتمهای ML که امروزه مورد استفاده قرار میگیرند تحت نظارت هستند. آنها با مجموعه داده های شناخته شده یا برچسب گذاری شده کار می کنند – به عنوان مثال، تصاویر سگ ها و گربه ها. دو نوع حیوان شناخته شده هستند، بنابراین مدیران می توانند تصاویر را قبل از دادن آنها به الگوریتم برچسب گذاری کنند.
الگوریتم های ML بدون نظارت از مجموعه داده های ناشناخته یاد می گیرند. برای مثال، ویدیوهای TikTok را در نظر بگیرید. ویدیوهای زیادی با موضوعات بسیار زیاد وجود دارد که آموزش الگوریتمی از آنها به صورت نظارت شده غیرممکن است. داده ها هنوز برچسب گذاری نشده اند.
الگوریتم های نیمه نظارت شده ML در ابتدا با مجموعه داده کوچکی که شناخته شده و برچسب گذاری شده است آموزش داده می شوند. سپس برای ادامه آموزش به یک مجموعه داده بدون برچسب بزرگتر اعمال می شود.
الگوریتم های تقویت شده ML در ابتدا آموزش داده نمی شوند. آنها در حال حرکت از آزمون و خطا یاد می گیرند. به رباتی فکر کنید که در حال یادگیری حرکت در انبوهی از سنگ ها است. هر بار که می افتد، یاد می گیرد که چه چیزی کار نمی کند، و رفتار خود را تغییر می دهد تا زمانی که موفق شود. به آموزش سگ و استفاده از خوراکی ها برای آموزش دستورات مختلف فکر کنید. با تقویت مثبت، سگ به اجرای دستورات ادامه می دهد و رفتاری را تغییر می دهد که پاسخ مطلوبی به او ندهد.
یادگیری ماشین تحت نظارت در مقابل یادگیری ماشینی بدون نظارت
یادگیری ماشین تحت نظارت
از مجموعه داده های شناخته شده، تثبیت شده و طبقه بندی شده برای یافتن الگوها استفاده می کند. بیایید ایده قبلی در مورد تصاویر سگ و گربه را گسترش دهیم. شما می توانید مجموعه داده ای عظیم پر از هزاران حیوان مختلف داشته باشید که در میلیون ها عکس نگهداری می شوند. از آنجایی که انواع حیوانات شناخته شده است، میتوان آنها را قبل از ارائه به الگوریتم نظارتشده ML گروهبندی و برچسبگذاری کرد تا درک آن را بیاموزد.
الگوریتم نظارت شده اکنون ورودی را با خروجی و تصویر را با برچسب نوع حیوان مقایسه می کند. در نهایت یاد میگیرد که نوع خاصی از حیوانات را در عکسهای جدیدی که با آن مواجه میشود، تشخیص دهد.
یادگیری ماشین بدون نظارت
الگوریتم های ML بدون نظارت امروزه مانند فیلترهای هرزنامه هستند. در ابتدا، مدیران میتوانستند فیلترهای هرزنامه را برنامهریزی کنند تا به دنبال کلمات خاصی در ایمیل بگردند تا هرزنامه را بفهمند. این دیگر امکان پذیر نیست، بنابراین بدون نظارت در اینجا به خوبی کار می کند. الگوریتم ML بدون نظارت به ایمیل هایی تغذیه می شود که برای شروع جستجوی الگوها برچسب گذاری نشده اند. با پیدا شدن آن الگوها، میآموزد که هرزنامه چه شکلی است و آن را در محیط تولید شناسایی میکند.
تکنیک های یادگیری ماشین
تکنیک های ML مشکلات را حل می کند. بسته به مشکلی که با آن مواجه هستید، تکنیک ML خاصی را انتخاب می کنید. در اینجا 6 مورد رایج وجود دارد.
تکنیک رگرسیون
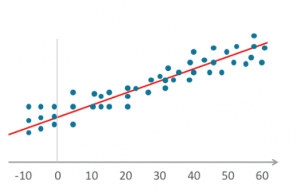
از رگرسیون می توان برای پیش بینی قیمت های بازار خانه یا تعیین قیمت بهینه فروش یک بیل برفی در مینه سوتا در ماه دسامبر استفاده کرد. رگرسیون می گوید که اگرچه قیمت ها در نوسان هستند، اما همیشه به قیمت متوسط باز می گردند، حتی اگر با گذشت زمان قیمت خانه ها افزایش یابد، یک میانگین وجود دارد که همیشه تکرار می شود. میتوانید قیمتها را در طول زمان بر روی یک نمودار رسم کنید و با گذشت زمان، میانگین را پیدا کنید. همانطور که خط قرمز در نمودار ادامه می یابد، پیش بینی های آینده را امکان پذیر می کند.
طبقه بندی
طبقه بندی برای گروه بندی داده ها به دسته های شناخته شده استفاده می شود. شما می توانید به دنبال مشتریانی باشید که به طور قابل پیش بینی مشتریان خوبی هستند (آنها همیشه برمی گردند و پول بیشتری خرج می کنند) یا به طور قابل پیش بینی می خواهند از جای دیگری شروع به خرید کنند. اگر بتوانید در طول زمان به گذشته نگاه کنید و پیشبینیکنندههایی را برای هر طبقهبندی از مشتریان بیابید، آن را برای مشتریان فعلی اعمال خواهید کرد و پیشبینی میکنید که آنها با کدام گروه مناسب هستند. در این صورت میتوانید به طور مؤثرتری بازاریابی کنید و احتمالاً مشتری را که به طور بالقوه ترک میکند به یک مشتری عالی بازگشته تبدیل کنید. این نمونه خوبی از ML تحت نظارت است.
خوشه بندی
بر خلاف تکنیک طبقه بندی، خوشه بندی ML بدون نظارت است. در خوشه بندی، سیستم نحوه گروه بندی داده هایی را که شما نمی دانید چگونه گروه بندی کنید، پیدا می کند. این نوع ML برای تجزیه و تحلیل تصاویر پزشکی، تجزیه و تحلیل شبکه های اجتماعی یا جستجوی ناهنجاری ها عالی است
Google از خوشهبندی برای تعمیم، فشردهسازی دادهها و حفظ حریم خصوصی در محصولاتی مانند ویدیوهای YouTube، برنامههای Play، و آهنگهای موسیقی استفاده میکند.
تشخیص ناهنجاری
تشخیص ناهنجاری زمانی استفاده می شود که شما به دنبال موارد دورتر هستید، مانند مشاهده گوسفند سیاه در گله. وقتی به حجم عظیمی از داده ها نگاه می کنیم، یافتن این ناهنجاری ها برای انسان غیرممکن است. اما، برای مثال، اگر یک دانشمند داده، دادههای صورتحساب پزشکی سیستمی را از بسیاری از بیمارستانها تغذیه کند، تشخیص ناهنجاری راهی برای گروهبندی صورتحساب پیدا میکند. ممکن است مجموعهای از موارد دور از ذهن را کشف کند که به نظر میرسد محل وقوع تقلب است.
تحلیل سبد بازار
منطق تحلیل سبد بازار امکان پیش بینی های آینده را فراهم می کند. یک مثال ساده – اگر مشتریان گوشت چرخ کرده، گوجه فرنگی و تاکو را در سبد خود قرار دهند، می توانید پیش بینی کنید که پنیر و خامه ترش اضافه کنند. این پیشبینیها را میتوان با ارائه پیشنهادهای ارزشمند به خریداران آنلاین برای مواردی که فراموش کردهاند یا برای کمک به گروهبندی محصولات در یک فروشگاه، برای ایجاد فروش بیشتر استفاده کرد.
دو استاد دانشگاه MIT از این رویکرد برای کشف “منشور شکست” استفاده کردند. همانطور که مشخص است، برخی از مشتریان محصولاتی را دوست دارند که شکست بخورند. اگر بتوانید آنها را شناسایی کنید، می توانید تعیین کنید که آیا به فروش یک محصول ادامه دهید یا خیر و از چه نوع بازاریابی برای افزایش فروش از مشتریان مناسب استفاده کنید.
داده های سری زمانی
داده های سری زمانی معمولاً در مورد بسیاری از ما با مانیتورهای تناسب اندام روی مچ دست جمع آوری می شود. میتواند ضربان قلب را در دقیقه جمعآوری کند، چند قدم در دقیقه یا ساعت برمیداریم و برخی اکنون حتی اشباع اکسیژن را در طول زمان اندازهگیری میکنند. با این دادهها، میتوان پیشبینی کرد که چه زمانی یک نفر در آینده اجرا میشود. همچنین میتوان دادههای مربوط به ماشینآلات را جمعآوری کرد و خرابی را پیشبینی کرد زیرا دادههای مبتنی بر زمان در مورد سطح ارتعاش، سطح نویز دسی بل و فشار وجود دارد.
الگوریتم های یادگیری ماشین
اگر قرار است ML از داده ها یاد بگیرد، چگونه الگوریتمی برای یادگیری و یافتن داده های آماری معنی دار طراحی می کنید؟ الگوریتمهای ML از فرآیند ML تحت نظارت، بدون نظارت یا تقویت پشتیبانی میکنند.
مهندسان داده تکههایی از کد مینویسند که الگوریتمهایی هستند که به ماشین اجازه میدهند دادهها را یاد بگیرند یا اهمیت پیدا کنند.
- بیایید به چند الگوریتم خاص که رایج ترین هستند نگاه کنیم. در اینجا 5 مورد برتر مورد استفاده امروز آورده شده است. الگوریتم های رگرسیون خطی با برازش متغیرهای مستقل و وابسته به یک نمودار و رسم یک خط مستقیم برای میانگین یا روند، یک رابطه برقرار می کنند. Merriam-Webster رگرسیون را اینگونه تعریف می کند: “تابعی که میانگین مقدار یک متغیر تصادفی را تحت شرایطی که یک یا چند متغیر مستقل دارای مقادیر مشخص شده باشند، به دست می دهد.” این تعریف برای رگرسیون لجستیک نیز صدق می کند.
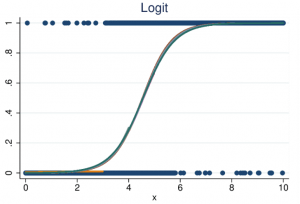
- رگرسیون لجستیک (با نام مستعار logit) نیز متغیرها را به یک نمودار منطبق میکند، همانطور که رگرسیون خطی نیز انجام میدهد، اما خط خطی نیست. خط در اینجا یک تابع سیگموئید است.
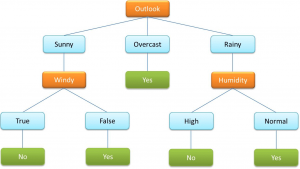
- درخت تصمیم یک الگوریتم بسیار رایج در ML نظارت شده است. برای طبقه بندی داده ها بر اساس متغیرهای طبقه ای و پیوسته استفاده می شود.
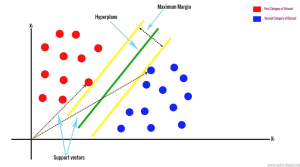
- ماشین بردار پشتیبان یک ابرصفحه را بر اساس دو نزدیکترین نقطه داده ترسیم می کند. این داده ها را با حاشیه سازی کلاس ها جدا می کند. داده ها را بر اساس فضای n بعدی طبقه بندی می کند. N تعداد ویژگی های مختلف شما را نشان می دهد.
- بیز ساده، احتمال یک نتیجه خاص را محاسبه می کند. این بسیار موثر است و از مدل های طبقه بندی پیچیده تر بهتر عمل می کند. یک مدل طبقهبندیکننده بیزی ساده متوجه میشود که هر ویژگی داده شده به وجود ویژگیهای خاص دیگر مرتبط نیست.

مدل های یادگیری ماشین
پس از ترکیب نوع ML (با نظارت، بدون نظارت و …)، تکنیک ها و الگوریتم ها، نتیجه فایلی است که آموزش داده شده است. اکنون می توان به این فایل داده های جدیدی داد و می تواند الگوها را تشخیص دهد و در صورت نیاز برای کسب و کار، مدیر یا مشتری پیش بینی یا تصمیم گیری کند.
بهترین زبان ها برای یادگیری ماشین
زبانهای یادگیری ماشین نحوهی نوشتن دستورالعملها برای یادگیری سیستم هستند. هر زبان یک جامعه کاربری برای پشتیبانی برای یادگیری یا راهنمایی دیگران دارد. در هر زبان کتابخانه هایی برای استفاده از یادگیری ماشین وجود دارد.
در اینجا 10 مورد برتر طبق نظرسنجی GitHub Top 10 در سال 2019 آمده است.
- Python
- C++
- JavaScript
- Java
- C#
- Julia
- Shell
- R
- TypeScript
- Scala – زبانی که برای تعامل با داده های بزرگ استفاده می شود.
یادگیری ماشین پایتون
از آنجایی که پایتون رایج ترین زبان ML است، در اینجا به طور خاص به آن می پردازیم.
پایتون یک زبان تفسیر شده، منبع باز و شی گرا است که نام آن از مونتی پایتون گرفته شده است. از آنجا که تفسیر می شود، قبل از اینکه توسط ماشین مجازی پایتون قابل اجرا باشد، به بایت کد تبدیل می شود.
ویژگیهای مختلفی وجود دارد که پایتون را به انتخابی ارجح برای ML تبدیل میکند.
- مجموعه بزرگی از بسته های قدرتمند که اکنون برای استفاده در دسترس هستند. بسته های ML خاصی مانند numpy، scipy و panda وجود دارد.
- نمونه سازی آسان و سریع
- ابزارهای مختلفی وجود دارد که امکان همکاری را فراهم می کند.
- همانطور که یک دانشمند داده از استخراج به مدل سازی و از طریق به روز رسانی راه حل ML خود حرکت می کند، پایتون می تواند همچنان زبان انتخابی باشد. دانشمند داده نیازی به تغییر زبان در حین حرکت در چرخه حیات ندارد.




